Pengertian Algoritma Naive Bayes
Algoritma Naive Bayes adalah sebuah metode pengklasifikasian yang berbasis pada metode probabilitas dan teorema Bayes. Algoritma ini digunakan untuk mengklasifikasikan data ke dalam kategori atau kelas yang telah ditentukan berdasarkan fitur-fitur atau atribut yang dimiliki oleh data tersebut.
Naive Bayes bekerja dengan menggunakan asumsi bahwa semua fitur yang digunakan untuk klasifikasi adalah independen satu sama lain, meskipun dalam situasi nyata, asumsi ini seringkali tidak sepenuhnya tepat.
Pada dasarnya, algoritma ini mencoba untuk menghitung probabilitas kelas atau kategori tertentu berdasarkan informasi yang ada dalam fitur-fitur data. Dalam konteks klasifikasi biner, misalnya “spam” atau “non-spam” dalam email, algoritma ini akan menghitung probabilitas masing-masing kelas berdasarkan kata-kata atau fitur-fitur yang ada dalam email tersebut, lalu memilih kelas dengan probabilitas tertinggi sebagai prediksi akhir.
Rumus
Rumus dasar dari Algoritma Naive Bayes adalah menggunakan Teorema Bayes untuk menghitung probabilitas kelas berdasarkan fitur-fitur yang ada dalam data. Pada dasarnya, kita ingin mencari probabilitas bahwa suatu data masuk ke dalam kelas tertentu (misalnya kelas A atau kelas B) berdasarkan fitur-fitur yang dimiliki oleh data tersebut.
Misalkan kita memiliki data dengan fitur-fitur X1, X2, X3, …, X, dan ingin mengklasifikasikannya ke dalam salah satu dari dua kelas, yaitu kelas A dan kelas B. Kita ingin mencari probabilitas bahwa data masuk ke dalam kelas A berdasarkan fitur-fitur tersebut.
Rumus dasar Teorema Bayes untuk Algoritma Naive Bayes adalah:
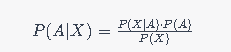
P(AIX) merupakan probabilitas kelas A (target) jika fitur-fitur X1, X2, X3,…, X, diberikan. P(XA) adalah probabilitas fitur-fitur X1, X2, X3,…, X, terjadi jika data masuk dalam kelas A.
P(A) sebagai prior dari kelas A, yaitu probabilitas kelas A tanpa mempertimbangkan fitur-fitur.
P(X) adalah probabilitas prior dari fitur-fitur X1, X2, X3,…, X, yaitu probabilitas fitur-fitur tersebut muncul secara keseluruhan.
Selanjutnya, dalam Naive Bayes, dilakukan asumsi bahwa semua fitur X1, X2, X3,…, Xn adalah independen satu sama lain, sehingga kita dapat menyederhanakan rumus sebagai berikut:
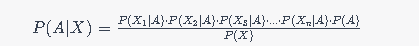
Dalam praktiknya, untuk melakukan klasifikasi menggunakan Algoritma Naive Bayes, kita akan menghitung probabilitas untuk setiap kelas yang ada (misalnya kelas A dan kelas B), dan memilih kelas dengan probabilitas tertinggi sebagai prediksi akhir untuk data tersebut
Langkah Metode Naive Bayes
Algoritma Naive Bayes bekerja dengan langkah-langkah berikut:
1. Jumlah Kelas / Label
Pertama-tama, kita perlu mengidentifikasi kelas atau label yang ingin kita prediksi. Misalnya, jika kita ingin mengklasifikasikan email menjadi “spam” atau “non-spam,” maka labelnya adalah “spam” dan “non-spam.”
2. Jumlah Kasus Per Kelas
Selanjutnya, kita akan menghitung berapa banyak kasus yang terdapat dalam setiap kelas. Misalnya, berapa banyak email yang dikategorikan sebagai “spam” dan berapa banyak yang dikategorikan sebagai “non-spam.”
3. Menghitung Probabilitas Setiap Variabel Kelas
Di sini, kita akan mencari probabilitas untuk setiap variabel dalam setiap kelas. Probabilitas ini akan memberi tahu kita seberapa sering suatu variabel muncul dalam suatu kelas tertentu.
4. Menggunakan Teorema Bayes untuk Prediksi
Setelah memiliki probabilitas variabel , kita dapat menggunakan Teorema Bayes untuk melakukan prediksi. Teorema Bayes membantu kita menghitung peluang terjadinya suatu kelas berdasarkan bukti yang kita miliki (probabilitas variabel kelas).
Alasan Menggunakan Metode Naive Bayes
Metode Naive Bayes memiliki beberapa alasan kuat untuk menjadi pilihan utama dalam pengklasifikasian data. Berikut adalah beberapa keunggulan utama dari metode ini:
1. Keberhasilan dalam Berbagai Kasus
Metode Naive Bayes telah terbukti berhasil dalam berbagai kasus pengklasifikasian. Sejumlah penelitian telah menunjukkan bahwa metode ini mampu memberikan tingkat akurasi yang lebih baik dibandingkan dengan metode klasifikasi lainnya
Keakuratannya yang tinggi menjadikan Naive Bayes sebagai pilihan utama dalam berbagai bidang, seperti analisis teks, deteksi spam email, klasifikasi gambar, dan banyak lagi.
2. Mudah Diterapkan
Salah satu daya tarik utama dari metode Naive Bayes adalah kemudahannya dalam penerapan. Metode ini dapat dengan cepat diimplementasikan tanpa memerlukan kompleksitas yang berlebihan. Bahkan dengan jumlah data pelatihan (training data) yang relatif sedikit, Naive Bayes mampu menghasilkan prediksi yang memuaskan. Kemudahan implementasi ini membuatnya menjadi pilihan ideal, terutama ketika waktu dan sumber daya terbatas.
3. Efisien dalam Penggunaan Data
Metode Naive Bayes merupakan pendekatan yang efisien dalam penggunaan data. Saat menerapkan Naive Bayes, kita tidak perlu memperhitungkan seluruh matriks kovarians data, yang dapat menjadi proses yang rumit dan memakan waktu.
Cukup dengan memusatkan perhatian pada varians dari suatu variabel dalam sebuah kelas, kita dapat dengan mudah menentukan klasifikasi data. Pendekatan ini tidak hanya menghemat waktu, tetapi juga memungkinkan algoritma untuk berjalan lebih cepat, membuatnya sangat ideal untuk data dalam skala besar.
Kekurangan algoritma Naive Bayes
Meskipun algoritma Naive Bayes memiliki banyak keunggulan, seperti yang telah dijelaskan sebelumnya, namun ada beberapa kekurangan yang perlu diperhatikan:
1. Asumsi Independensi yang Kuat (Naïf)
Salah satu asumsi utama dari Naive Bayes adalah independensi antar atribut atau fitur yang digunakan dalam proses klasifikasi. Asumsi ini sering kali tidak cocok dengan situasi nyata, karena beberapa atribut dapat berkaitan atau saling mempengaruhi dalam data yang kompleks. Karena itu, Naive Bayes mungkin tidak memberikan hasil yang optimal ketika terdapat ketergantungan antar atribut.
2. Sensitivitas terhadap Data Outlier
Naive Bayes dapat menjadi sensitif terhadap data outlier atau nilai ekstrim dalam data pelatihan. Data outlier dapat menyebabkan distribusi probabilitas yang tidak tepat, dan akibatnya, performa klasifikasi dapat menurun. Oleh karena itu, penting untuk memeriksa dan mengelola data outlier sebelum mengaplikasikan algoritma Naive Bayes.
3. Tidak Mampu Menangani Informasi Kontekstual
Naive Bayes mengandalkan probabilitas dan frekuensi kemunculan fitur dalam kelas untuk melakukan klasifikasi. Namun, algoritma ini tidak mampu menangkap informasi kontekstual yang lebih kompleks, seperti urutan data atau ketergantungan temporal. Sebagai contoh, dalam analisis teks, urutan kata dalam kalimat dapat memiliki arti yang berbeda, yang tidak dapat ditangkap oleh Naive Bayes.
4. Pengaruh Kata Kunci yang Tinggi
Dalam analisis teks, kata-kata kunci yang muncul sering kali memiliki dampak besar pada klasifikasi, sementara kata-kata yang lebih jarang muncul dapat diabaikan. Hal ini bisa menyebabkan hasil klasifikasi menjadi bias dan tidak memperhitungkan konteks keseluruhan dari teks tersebut..
Dalam dunia klasifikasi, algoritma Naive Bayes menjadi salah satu pilihan yang populer karena kemampuannya dalam mengklasifikasikan data dengan memanfaatkan metode probabilitas. Langkah-langkahnya yang sederhana membuat metode ini mudah diterapkan dan efisien dalam penggunaan data.

{kind=link}